Side-by-side Comparsion with Consistent4D
Results are from the official webpage of Consistent4D, where only two selected novel views are provided. Note that our approach requires sigificant less optimization time (15 mins v.s. 2 hours)











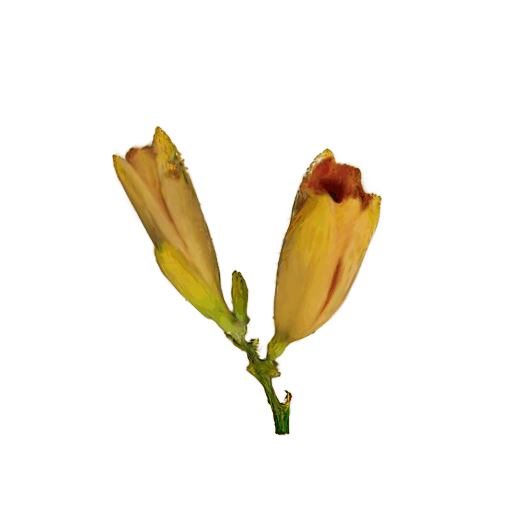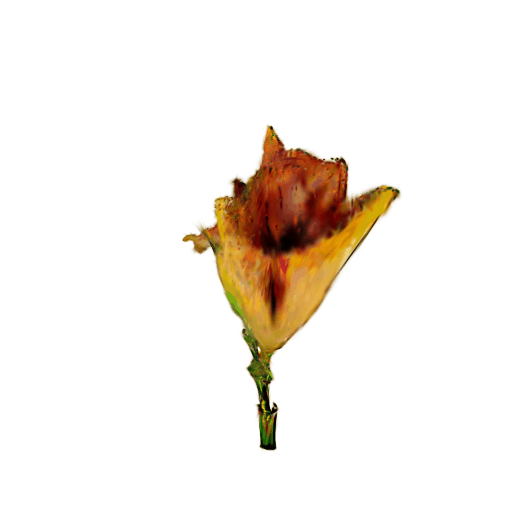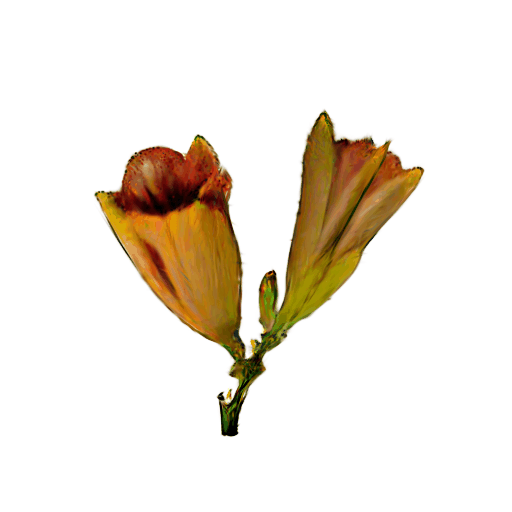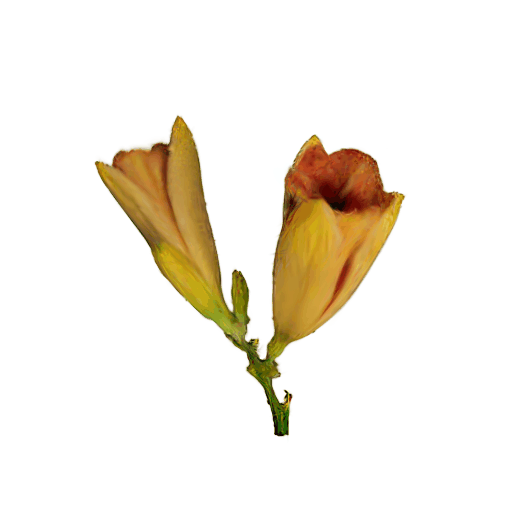











More Rresults
Side-by-side Comparsion with Consistent4D
Results are from the official webpage of Consistent4D, where only two selected novel views are provided. Note that our approach requires sigificant less optimization time (15 mins v.s. 2 hours)
Side-by-side comparison with 4DGen
4DGen results are from their official video.
Input Videos
Ours
4DGen
Driving videos
Top: Driving videos. Bottom: generated 4D.
























Texture Refinement: image-to-image v.s. video-to-video
Image-to-image refinement results in clear flickering on the back of the tiger.


Comparison Between Different Motion Representation
Motion representation is critical to 4D generation.




Effect of HexPlane Resolutions
We show results of different HexPlane resolutions.





Bird Flapping Wings
Example of bird flapping wings, compared with Animate124 and Dream-in-4D.




Ice Cream Melting
We show an example of an ice cream melting.



Failure Cases
Failure mode 1: low quality video generated by Stable Video Diffusion. The generated horse motion is temporarily inconsistent.


Failure mode 2: low quality 3D generated by DreamGaussianHD. The back of the minion is wrongly textured.


Failure mode 3: unnatural deformation. The top of the elephant nose is wrongly moved to its right hand.



Refinement Ablation
Final results



Refined results using differnt T in the video-to-video pipeline (without refence view reconstruction loss by default).
T=[0.7,0.95] denotes linearly decaying T from 0.7 to 0.95.




Refined videos by SVD at different T.





Training Iterations
Longer training schudules do not bring visible corrections to the foot motion.



Diverse motions
We show 10 more different 3D motions as a supplementary to Figure. 10 in the main paper.










Dynamic Cameras
Our approach does not require the camera to be static. We show three examples when the camera rotates, shifts, and closes up.
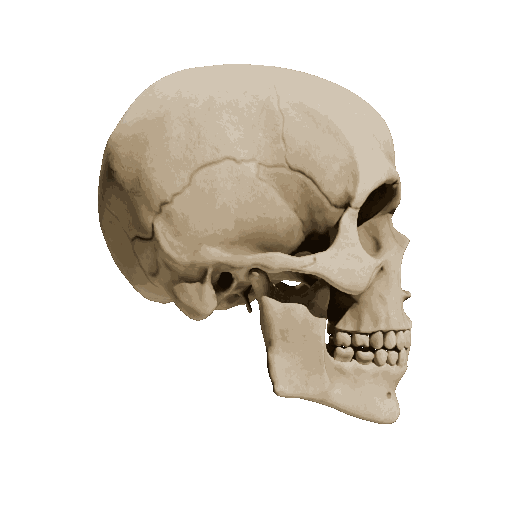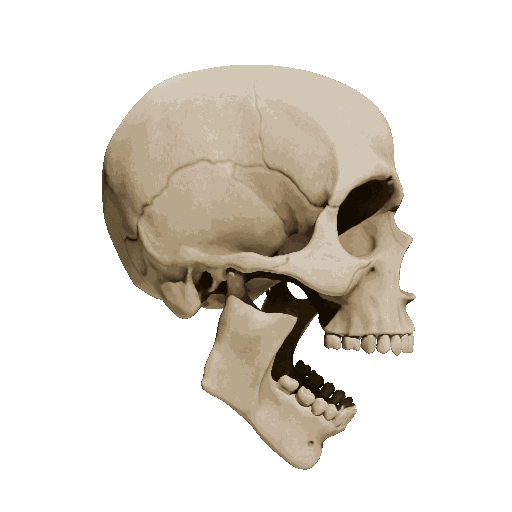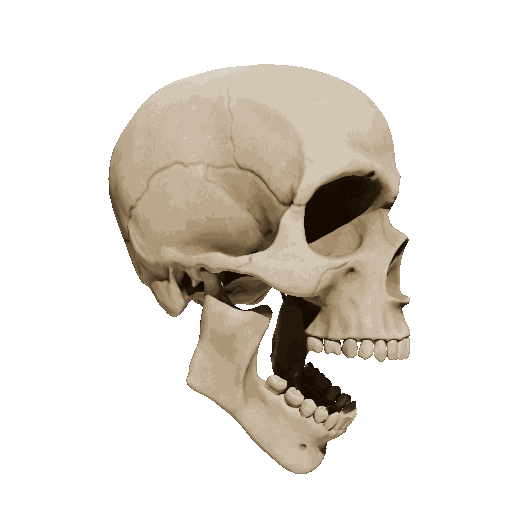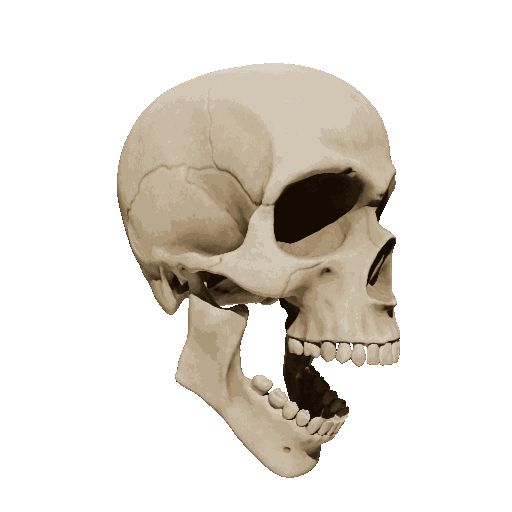
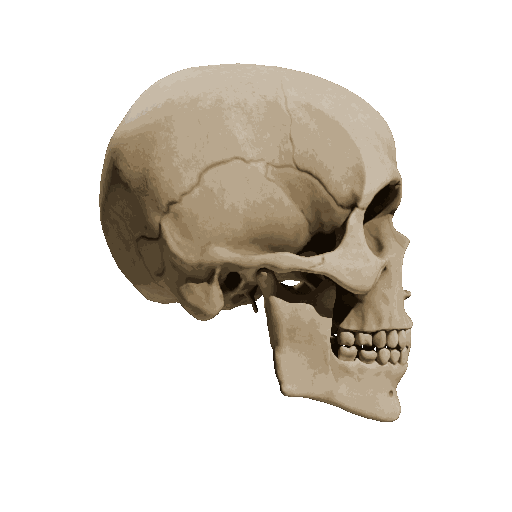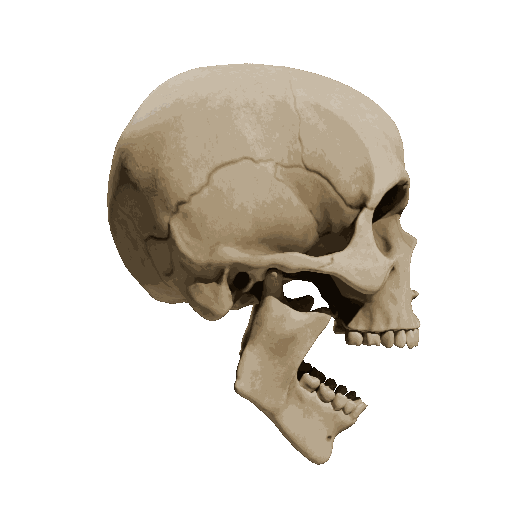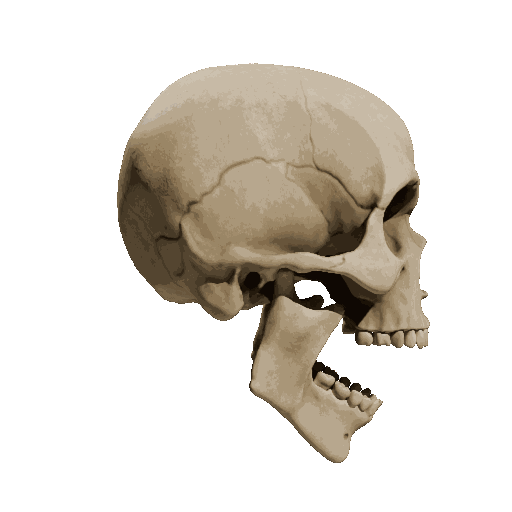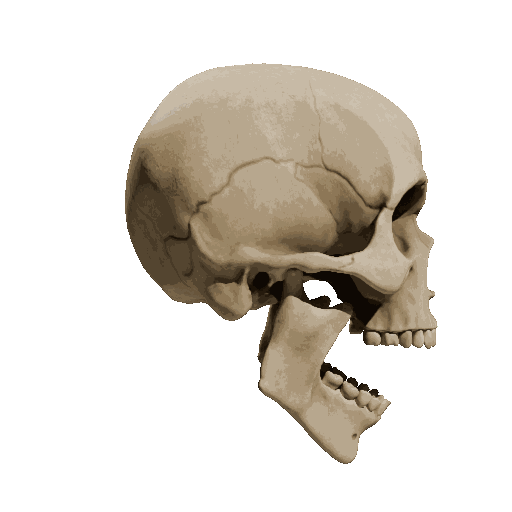
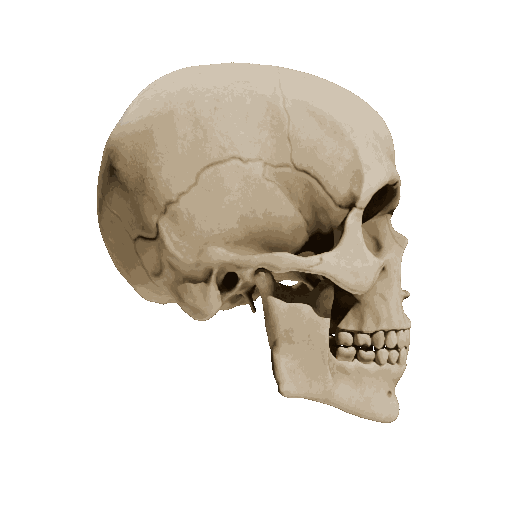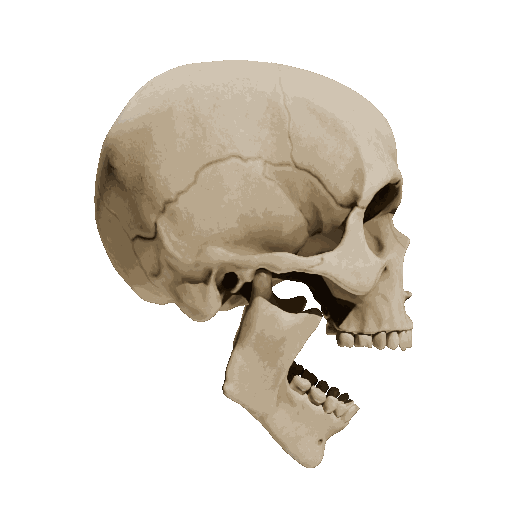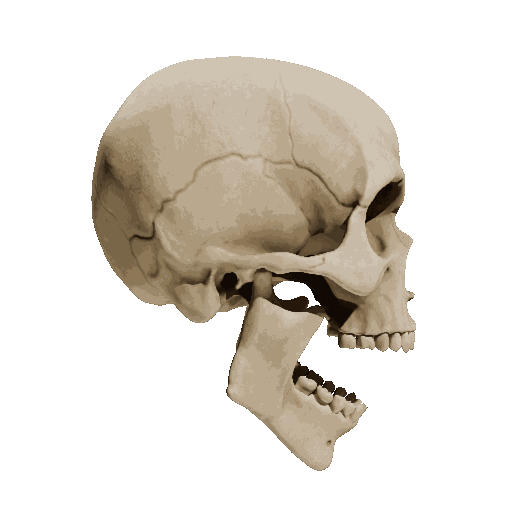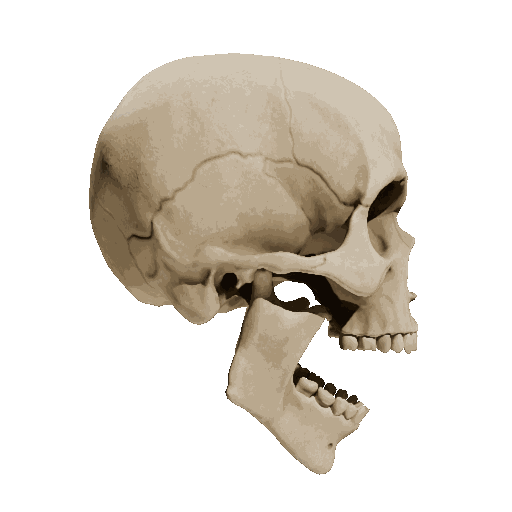
Temporal loss
We try different weights of temporal loss but observe limited or no improvement. weight=10 is the setting we report in the submission.




